Summary
この文書の要点
- 生成、埋め込み、リランキングを同じ抽象化に押し込まない。
- モデル名やAPIキーは設定で切り替え、業務ロジックに持ち込まない。
- 生成結果の型には、本文だけでなく引用、使用量、完了理由、モデル識別子を持たせる。
- 切り替え可能性は設定値ではなく、評価データ、ログ、フォールバック方針とセットで設計する。
どこが設計の難所か
RAGでは、検索結果をプロンプトへ渡す処理だけでなく、文書分割、埋め込み、検索、再順位付け、回答生成、引用表示が連鎖します。ここでAIプロバイダ固有のレスポンス形式や例外処理を各層に直接書くと、モデル変更のたびに広い範囲を直すことになります。
一方で、完全に汎用化しすぎると各プロバイダの強みを使えません。ストリーミング、JSON出力、tool calling、埋め込み次元数、料金、レート制限は異なります。境界を作る目的は差を消すことではなく、差がどこに現れるかを制御することです。
RAG基盤で後から効いてくるのは、モデル名の切り替えではなく、同じ質問に対する振る舞いの差です。JSON出力が強いモデル、長文の引用に強いモデル、低遅延だが根拠の扱いが粗いモデルを同じインターフェースで扱うには、成功と失敗の定義を業務側で持つ必要があります。
境界をどう切るか
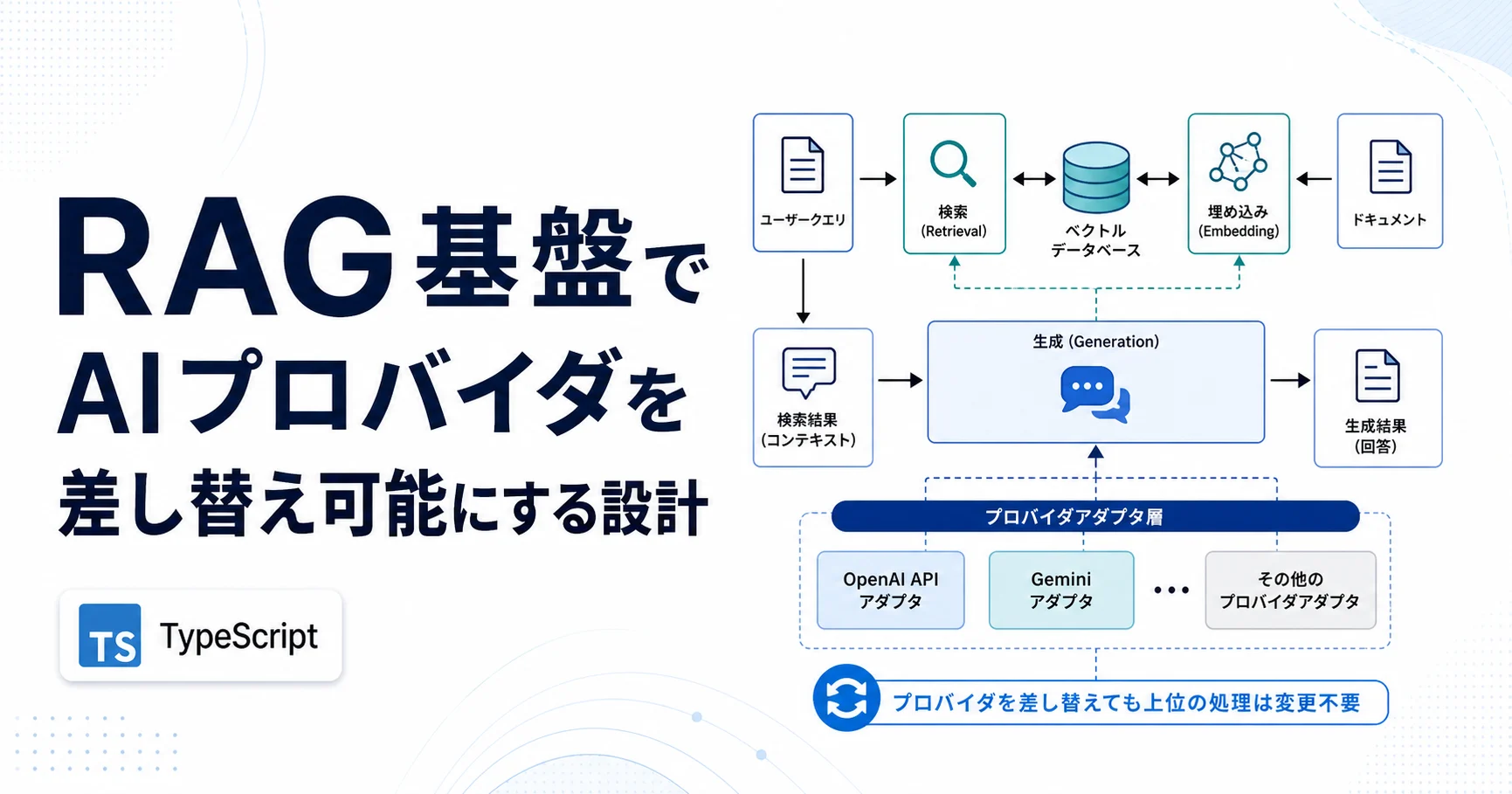
設計では、生成、埋め込み、リランキングを別々のポートとして定義します。業務側は「質問と文脈から回答候補を得る」「テキストをベクトル化する」「候補文書を並べ替える」という意味だけを見るようにし、具体的なOpenAI APIやGeminiの呼び出しはアダプタに閉じ込めます。
生成、埋め込み、リランキングのポートは似て見えても、寿命の違う契約です。生成ポートはストリーミングやtool callingで変わりやすく、埋め込みポートは次元数と距離関数でデータ構造に残ります。この差を意識して、差し替えの粒度をAPI呼び出し単位ではなくデータ資産の単位で分けます。
実装で効く細部
TypeScriptやPythonでは、入力と出力の型を先に決めます。生成結果には本文、引用ID、使用トークン、完了理由を含め、例外は認証失敗、レート制限、タイムアウト、品質上の失敗に分けます。埋め込みでは次元数と正規化有無をメタデータとして保存し、異なるモデルのベクトルを同じインデックスに混ぜないようにします。
実装では、`ModelInvocation`のような呼び出し記録を全プロバイダで共通化し、入力トークン、出力トークン、temperature、検索結果ID、リトライ回数を保存します。回答本文よりも、どの文脈を渡してどのモデルがどの理由で終了したかが、後日の品質改善に効きます。
- 埋め込みモデルの変更時は、新旧ベクトルを同じインデックスへ混ぜず、index_versionで分離する。
- ストリーミングレスポンスはUI都合の形式にせず、チャンク、完了、失敗をイベントとして表現する。
- フォールバック先の回答にはモデル識別子を残し、品質劣化をログ上で追えるようにする。
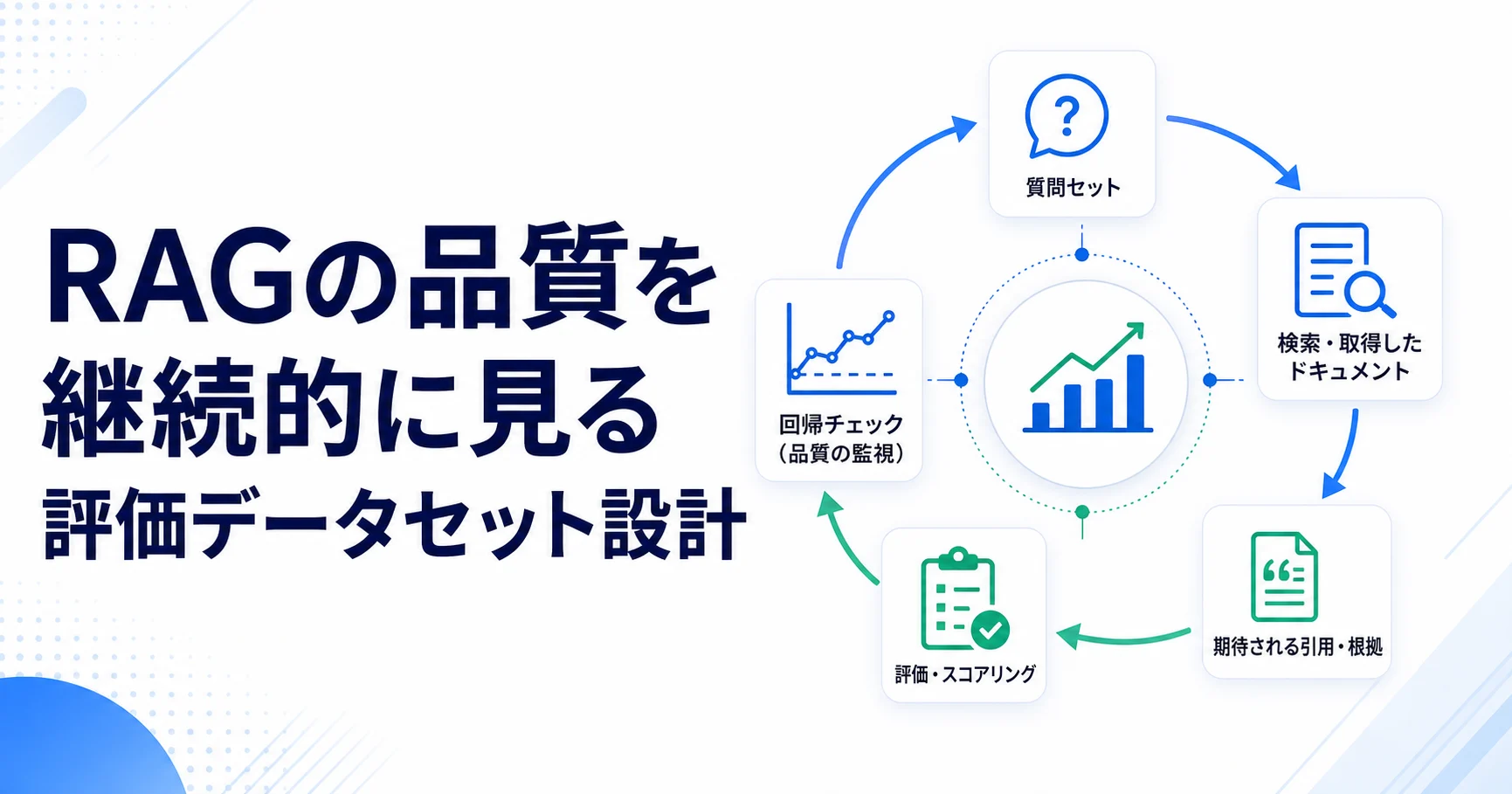
壊れ方を観測する
検証では、同じ質問セットを複数プロバイダで実行し、正答率だけでなく引用の妥当性、不要な断定、応答時間、失敗率を比較します。自動評価だけに頼らず、業務上の誤回答が大きな問題になる質問をゴールデンセットとして残すことが重要です。
検証では、同じ評価セットをプロバイダ別に走らせ、回答の正しさだけでなく、引用漏れ、根拠外の補完、拒否すべき質問への応答を比較します。モデルを変えても壊れていないかではなく、どの種類の質問で壊れ方が変わるかを見ると、運用上の判断がしやすくなります。
捨てた選択肢とトレードオフ
抽象化を厚くすると、モデル固有機能を使うたびにインターフェースを拡張する必要があります。逆に薄くしすぎると差し替え時に業務コードへ影響します。初期段階では共通化する範囲を小さくし、生成と埋め込みを分けるだけでも十分な効果があります。
抽象化を強くすると新機能の利用が遅れ、薄くすると切り替え時の影響が大きくなります。現実的には、業務ロジックから隠す層と、モデル固有機能を明示的に使う層を分け、固有機能を使った場所を後から検索できる状態にする方が保守しやすいです。
現場に残す判断軸
AIプロバイダを切り替えられる設計とは、どのモデルでも同じ回答になる設計ではありません。差分が出る場所を限定し、評価でその差を見えるようにすることが、RAG基盤を長く運用するための現実的な判断軸です。
プロバイダ非依存という言葉だけでは設計になりません。どの差分を吸収し、どの差分を露出させ、どの差分を評価で監視するかを分けることが、RAGを長く使うための技術的な芯になります。