Summary
この文書の要点
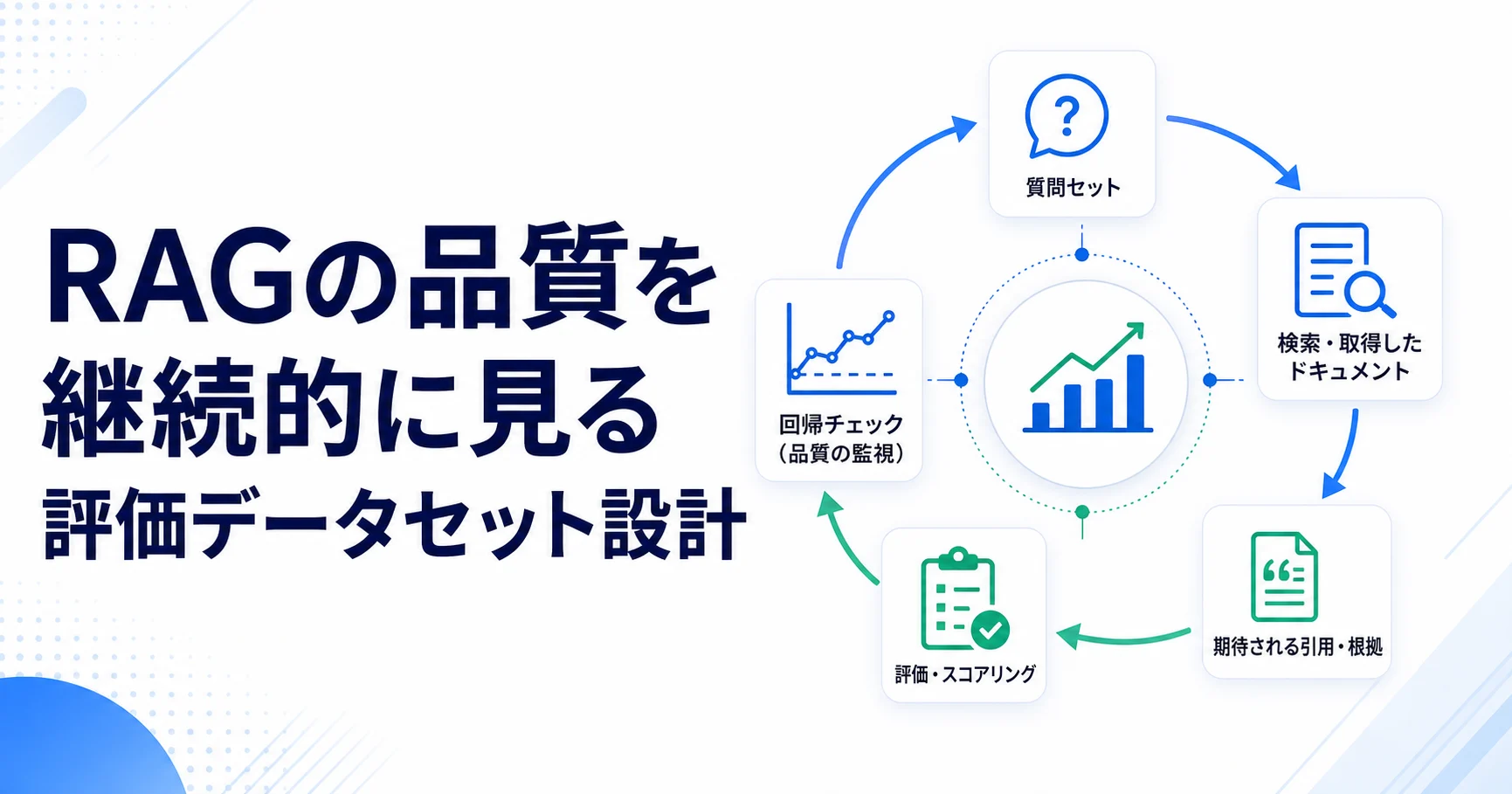
- 質問セットは正常系だけでなく、答えられない質問も含める。
- 期待する引用元を記録し、回答文だけで評価しない。
- 質問ごとに期待文書、許容回答、禁止回答、重要度を分けて保存する。
- 評価結果は点数だけでなく、検索段階と生成段階の失敗分類として残す。
どこが設計の難所か
RAGの品質確認を担当者の目視だけにすると、改善したのか悪化したのかを説明しづらくなります。特に文書が増えた時、以前は正しく答えられていた質問が別の文書に引っ張られることがあります。
すべての業務質問を評価データにすることはできません。また、AIの回答は毎回完全には一致しません。評価は厳密な単体テストではなく、運用上のリスクが増えていないかを見る回帰テストとして設計する方が現実的です。
RAGの品質は、文書が増えるほど単純には上がりません。似た文書が増えると検索順位が揺れ、古い手順と新しい手順が混ざり、プロンプトは長くなります。評価セットは、この揺れを感覚ではなく差分として扱うための最低限の基盤です。
境界をどう切るか
評価データは、質問、期待する根拠文書、望ましい回答の要点、答えてはいけない条件を持たせます。検索結果の上位に期待文書が入っているか、回答が根拠に沿っているか、根拠がない時に無理に答えていないかを分けて見ます。
評価データは、質問、期待する根拠、回答に含める要点、答えてはいけない条件を分けます。たとえば同じ質問でも、検索が正しい文書に到達したか、生成が要点を落としていないか、根拠がない時に拒否できたかは別の評価軸です。
実装で効く細部
データはJSONやCSVで管理し、質問ごとにカテゴリと重要度を付けます。自動評価では、検索段階のrecall、回答段階の要点一致、引用IDの一致、禁止表現の有無を確認します。LLM-as-a-judgeを使う場合でも、判定プロンプトと判定理由を保存し、評価自体の変化を追えるようにします。
実装では、評価ケースをJSONで管理し、`question_id`、`expected_chunk_ids`、`must_include`、`must_not_include`、`risk_level`を持たせます。実行結果には検索上位、プロンプト長、回答、引用、判定理由を保存し、後から失敗ケースだけを再実行できるようにします。
- 検索評価はtop-k内に期待チャンクが入るかを見る。生成評価とは分けて扱う。
- LLM-as-a-judgeを使う場合も、判定プロンプトと判定モデルのバージョンを保存する。
- 答えられない質問を必ず含め、無理に回答する失敗を検出する。
壊れ方を観測する
CIでは全件を毎回実行するのではなく、重要度の高い小さなセットを回します。夜間や手動ジョブで広いセットを実行し、変更前後の差分をレポートします。失敗した質問は、検索、文書分割、プロンプト、モデル、データ不足のどこに原因があるかを分類します。
CIでは全ケースを毎回走らせるより、重要度の高い小さなセットで回帰を見る方が続きます。広いセットは夜間ジョブや手動実行に回し、検索recall、引用一致、禁止表現、応答時間の差分を前回結果と比較します。
捨てた選択肢とトレードオフ
評価データを増やしすぎると実行時間と確認コストが大きくなります。逆に少なすぎると代表性がありません。最初は業務上の影響が大きい20問程度から始め、障害や問い合わせをきっかけに追加する運用が続きやすいです。
評価を厳密にしすぎると、表現の揺れまで失敗扱いになり、開発速度を落とします。逆に緩すぎると品質劣化を見逃します。業務上のリスクが高い質問だけ判定を厳しくし、低リスクの質問は傾向を見る、という強弱が必要です。
現場に残す判断軸
RAGの評価は、AIの賢さを一度だけ測る作業ではありません。文書とモデルが変わり続ける前提で、悪化を早く見つける仕組みを作ることが、実務で使えるRAGに近づける第一歩です。
RAGの改善は、プロンプトを何度も触る作業ではなく、壊れ方を分類して再現できるようにする作業です。評価データセットは、その分類をチームで共有するための設計資産になります。