Summary
この文書の要点
- OpenAPIの主な目的は、きれいなSwagger画面を作ることではなく、実装と仕様のずれを小さく保つことです。
- 各バックエンドが自分の`/openapi.json`を生成し、別の集約層がマージする構成にすると、サービス境界を保ったまま全体像を見られます。
- `describeRoute`はメタデータとして追記し、既存の検証ミドルウェアは無理に置き換えない方が、安全に段階移行できます。
- 未注釈のルートも棚卸しに出し、summaryやtagsの欠落を検出することで、仕様整備を継続的な運用にできます。
手書きのAPI仕様は、実装より早く古くなります。
OpenAPIは、APIの利用者にとっても、実装者にとっても便利な共通言語です。エンドポイント、入力、レスポンス、認証、エラーを一つの仕様として読めるため、フロントエンド実装、外部連携、テスト設計、運用確認の足場になります。
ただし、OpenAPIを手書きで管理すると、実装と仕様の二重管理になります。実装ではZodなどのスキーマで入力検証を行い、別ファイルではOpenAPIのschemaを手で書く。短期的には動きますが、変更のたびに同じ意味を二箇所へ反映する必要があります。片方だけ直ると、仕様は正しそうに見えるだけの古い文書になります。
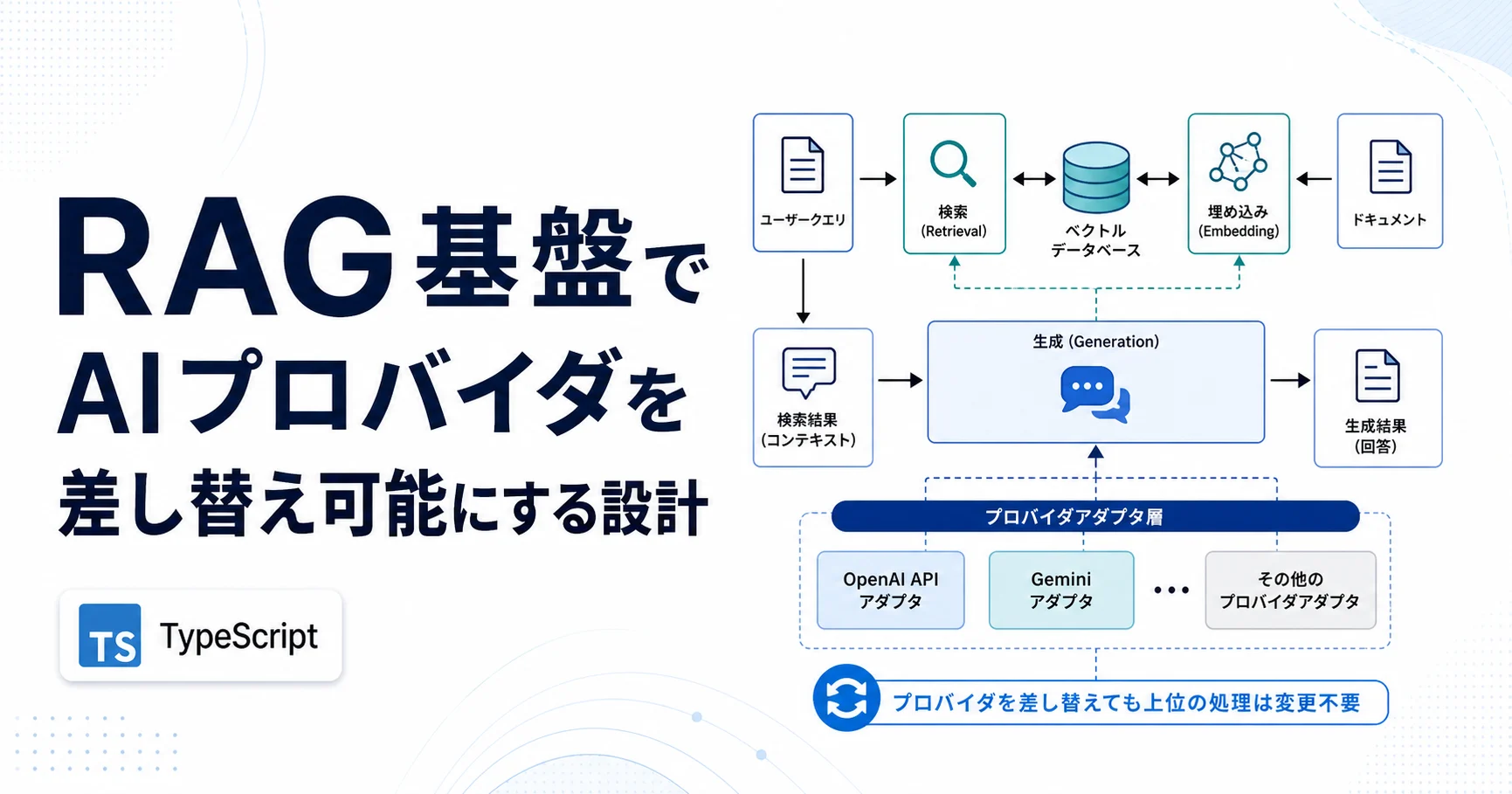
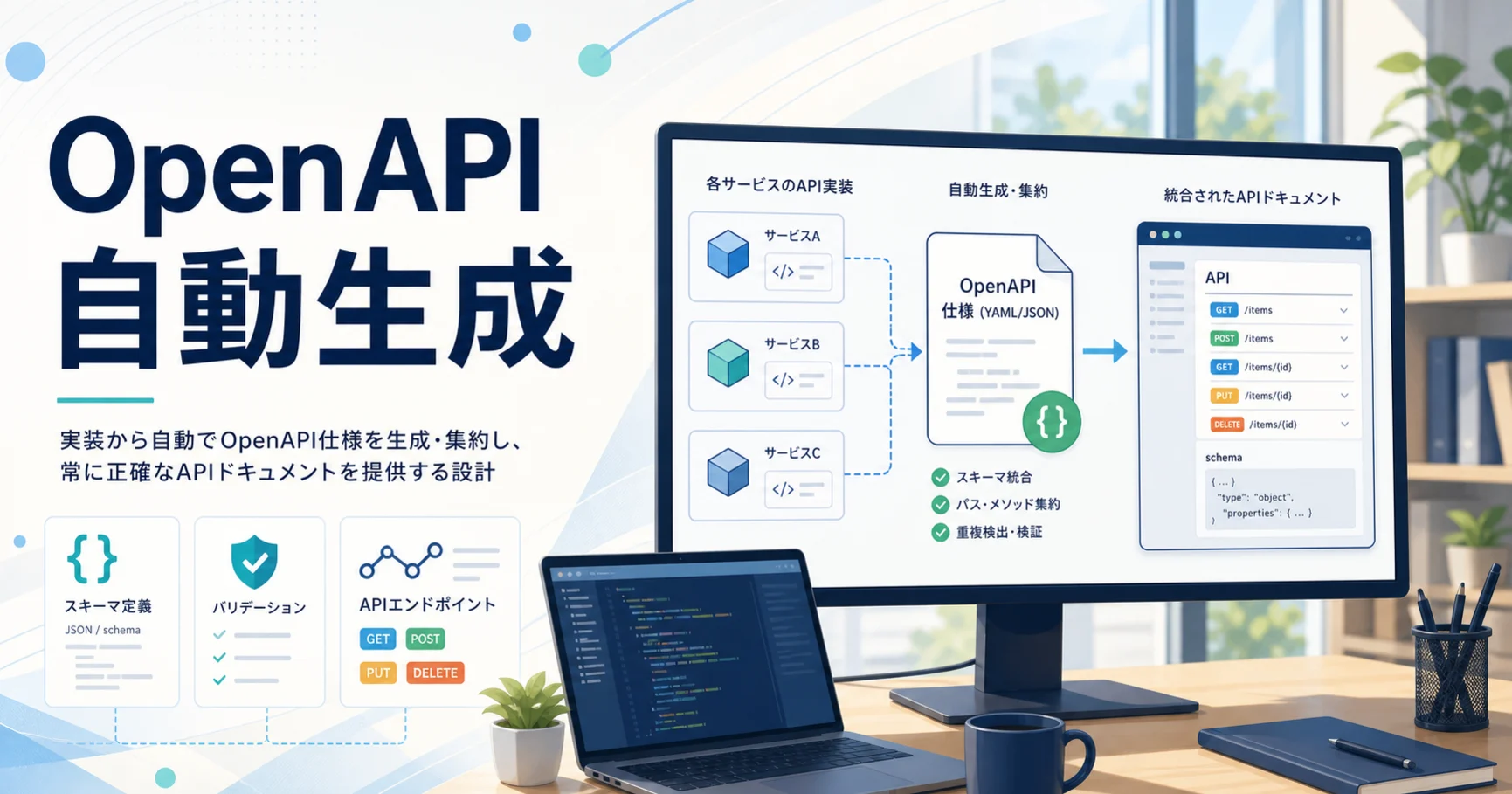
特に、複数のHonoバックエンドやドメイン別のAPIがある構成では、どのサービスがどのAPIを持っているかを把握しづらくなります。個別のSwagger UIがあっても、全体の検索、タグの統一、スキーマの衝突、認証方式の見通しは別の問題です。本稿では、実装に近い場所からOpenAPIを自動生成し、統合ビューへ集約する設計を整理します。
目標はSwaggerを増やすことではなく、仕様のドリフトを減らすことです。
APIドキュメント整備の議論では、しばしば「見やすいSwaggerを出したい」という話になります。しかし本質的な課題は表示画面ではありません。実装と仕様がずれること、ずれに気づけないこと、ずれた仕様を信じて開発や検証が進むことです。
この問題に対しては、仕様を実装へ近づける必要があります。入力検証に使っているZodスキーマ、ルート定義、認証境界、レスポンスの代表形を、できるだけ実装と同じ場所で記述します。OpenAPI専用の巨大な手書きファイルを作るのではなく、ルートごとのメタデータとして仕様を育てます。
もう一つの目標は、全体像を失わないことです。サービスを分割すると、責務は明確になりますが、利用者から見たAPIの一覧性は落ちます。そこで、各サービスは自分の仕様だけを生成し、統合ビューは別の集約層で作ります。これにより、サービス境界と一覧性を両立できます。
- 仕様の正しさは、実装と同じ変更サイクルで更新されることで保つ。
- 各バックエンドは自分の`GET /openapi.json`だけに責任を持つ。
- 統合ビューは各specを取得して束ねるだけにし、業務ロジックや認証処理を持たせない。
- API利用者には検索可能な1枚のリファレンスを提供し、実装者にはサービス単位のデバッグ導線を残す。
分散生成とマージを基本構成にします。
基本構成は単純です。各Honoバックエンドが`openAPIRouteHandler`で自分の`/openapi.json`を生成します。個別の確認用に`/docs`を持たせてもよいですが、人が日常的に見る統合リファレンスは別サービスまたは別ルートで提供します。
集約層は、サービス一覧をもとに各`/openapi.json`を取得し、OpenAPI 3.1のドキュメントとしてマージします。pathsを統合し、operationに出自を示すメタデータを付け、components.schemasにはサービス名のプレフィックスを付けて衝突を避けます。認証方式の定義は共通化し、サービスごとの差分を小さく保ちます。
この設計では、特定のゲートウェイが全サービスの仕様を抱え込む必要がありません。集約層は仕様を読むだけで、実APIのプロキシや認証判断をしません。サービス追加時は、サービス側に`/openapi.json`を設け、集約対象の一覧に1行追加する。運用の単位をそれくらい小さくしておくと、横展開しやすくなります。
既存ルートには、メタデータを追記する形で移行します。
既存のAPIがある場合、OpenAPI対応のためにルート定義を全面的に書き換えるのは危険です。入力検証、エラー本文、`c.req.valid()`の使い方、テストの期待値が少し変わるだけでも、APIの振る舞いが変わる可能性があります。
そのため、まずは`hono-openapi`の`describeRoute`をメタデータとして追記する方針が扱いやすいです。summary、tags、responsesをルートの近くに置き、既存の`zValidator`などの検証ミドルウェアは温存します。OpenAPIのために検証の実装を変えるのではなく、仕様の説明を追加するという順番です。
注意点もあります。例えば、リクエストボディのschemaをresponses用のresolverと同じ感覚で書くと、型や実行時の問題につながることがあります。ライブラリの都合に合わせてAPI実装を曲げるのではなく、実装挙動を守りながら、summaryやdescriptionで入力の意味を補足する判断も必要です。
- `describeRoute`は、実装の近くに置く仕様メタデータとして扱う。
- 既存の入力検証は、挙動が変わらない限り無理に置き換えない。
- CORSプリフライト、health check、内部ユーティリティのようなルートは仕様から除外する。
- spec生成結果はキャッシュされる場合があるため、反映確認ではバックエンド再起動や再ビルドの要否も手順に含める。
未注釈ルートを見える化し、棚卸しから始めます。
全ルートを一度にきれいなOpenAPIへ移す必要はありません。むしろ、いきなり完全なschemaを目指すと、移行が止まりやすくなります。最初の目的は、どのサービスにどのpathとmethodが存在するかを見える化することです。
`includeEmptyPaths`のような棚卸し設定を使うと、注釈前のルートも一覧に出せます。schemaは空でも、pathとmethodが見えるだけで大きな前進です。そこからsummaryやtagsがないoperationを数え、優先度の高いドメインから注釈を進めます。
この棚卸しは、実装上の設計レビューにもなります。似た名前のエンドポイント、ドメインをまたいだ重複、認証境界が曖昧なAPI、使われていない古いAPIが見つかります。OpenAPI対応はドキュメント整備であると同時に、API設計の在庫整理でもあります。
統合時は、衝突と出自を明示します。
複数サービスのspecを単純に結合すると、components.schemasの名前が衝突します。例えば、複数のサービスが`User`や`ErrorResponse`というschema名を持つことは自然です。そのまま混ぜると、どの`User`を参照しているのか分からなくなります。
集約層では、schema名にサービス単位の名前空間を付け、`$ref`も貼り替えます。pathsが衝突した場合は警告を出し、どのサービスの定義が採用されたかを明示します。operationには`x-service`のような拡張情報を付け、統合ビューから出自を追えるようにします。
UIはSwagger UIでも構いませんが、複数サービスを検索・閲覧する統合用途ではScalarのようなAPIリファレンスUIも選択肢になります。重要なのはUIの種類ではなく、ブラウザが各サービスへ直接fetchしない構成にすることです。集約済みのspecを同一オリジンで配信すれば、CORSや認証の複雑さをUIへ持ち込まずに済みます。
API仕様は便利ですが、公開範囲を誤ると情報露出になります。
OpenAPIには、path、method、入力項目、レスポンス、認証方式など、攻撃者にも有用な情報が含まれます。公開APIなら公開してよい情報ですが、管理画面向けAPIや内部処理APIまで無条件に公開するべきではありません。
本番環境では、統合ドキュメントの閲覧に管理者権限を要求する、公開APIと管理APIでdocsを分ける、内部サービスのspecをCI成果物としてだけ保持する、といった判断が必要です。OpenAPIを整備することと、すべてのAPI構造をインターネットに出すことは別です。
また、descriptionに内部事情を書きすぎないことも重要です。運用者向けの注意、チケット番号、内部URL、障害履歴、顧客固有の業務語彙は、OpenAPIの説明文へ入れない方が安全です。公開してよい抽象度で書く、という基準は技術文書と同じです。
CIでは、生成できることと欠落が増えないことを確認します。
OpenAPI自動生成は、一度入れて終わりではありません。ルートが増えたときにspecへ出るか、summaryやtagsのないoperationが増えていないか、componentsの参照が壊れていないかを継続的に確認します。
CIでは、各サービスのspecをファイルとして出力し、集約処理を実行します。ネットワーク越しに起動中サービスへ依存するより、ビルド成果物として検証した方が安定する場面があります。集約時のwarningsをテストで扱い、paths衝突やschema参照切れを見逃さないようにします。
完全性を急ぎすぎると移行が止まります。最初は、`/openapi.json`が生成できること、全pathが棚卸しに出ること、統合ビューが壊れないことを合格ラインにします。その後、主要APIからsummary、tags、responses、認証方式、代表的なschemaを足していきます。
- 生成チェック:各サービスの`/openapi.json`が構文的に正しいOpenAPIとして出力される。
- 集約チェック:schema名の衝突、`$ref`切れ、paths衝突をwarningsとして扱う。
- 欠落チェック:summaryやtagsのないoperation数を定点観測する。
- 回帰チェック:既存テストの入力検証、エラー本文、ステータスコードがOpenAPI対応で変わっていないことを確認する。
自動生成にも限界があります。
自動生成は、実装から分かることを仕様へ近づける仕組みです。逆に言えば、実装だけでは分からない業務上の意味、エラー時の利用者向け説明、変更互換性、レート制限、運用上の注意は、人が書く必要があります。
また、OpenAPI対応のためにルートファイルへメタデータが増えます。読みやすさを保つには、タグ命名、レスポンス記述の粒度、共通schemaの置き場所を決めておく必要があります。すべてを厳密に書こうとすると実装速度が落ち、粗すぎるとドキュメントとして使えません。
現実的な基準は、利用者が誤実装しやすい部分から詳しく書くことです。認証が必要か、入力の必須項目は何か、成功時の代表形は何か、エラー時のステータスコードは何か。まずここを揃えるだけでも、API利用者と実装者の認識差はかなり小さくなります。
OpenAPIは、実装と運用をつなぐ継続的な設計資産です。
OpenAPIを手書きの成果物として扱うと、更新されない仕様書になりがちです。実装に近い場所でメタデータを追記し、各バックエンドが自分のspecを生成し、集約層が全体を束ねる。この構成にすると、仕様は実装変更の近くで保守されます。
大切なのは、最初から完璧なschemaを作ることではありません。まず全ルートを棚卸しし、主要APIから注釈を足し、CIで生成と集約を検証する。仕様を一度の作業ではなく、日々の変更に追従する運用へ変えることが、APIドキュメントを長く使える状態にします。