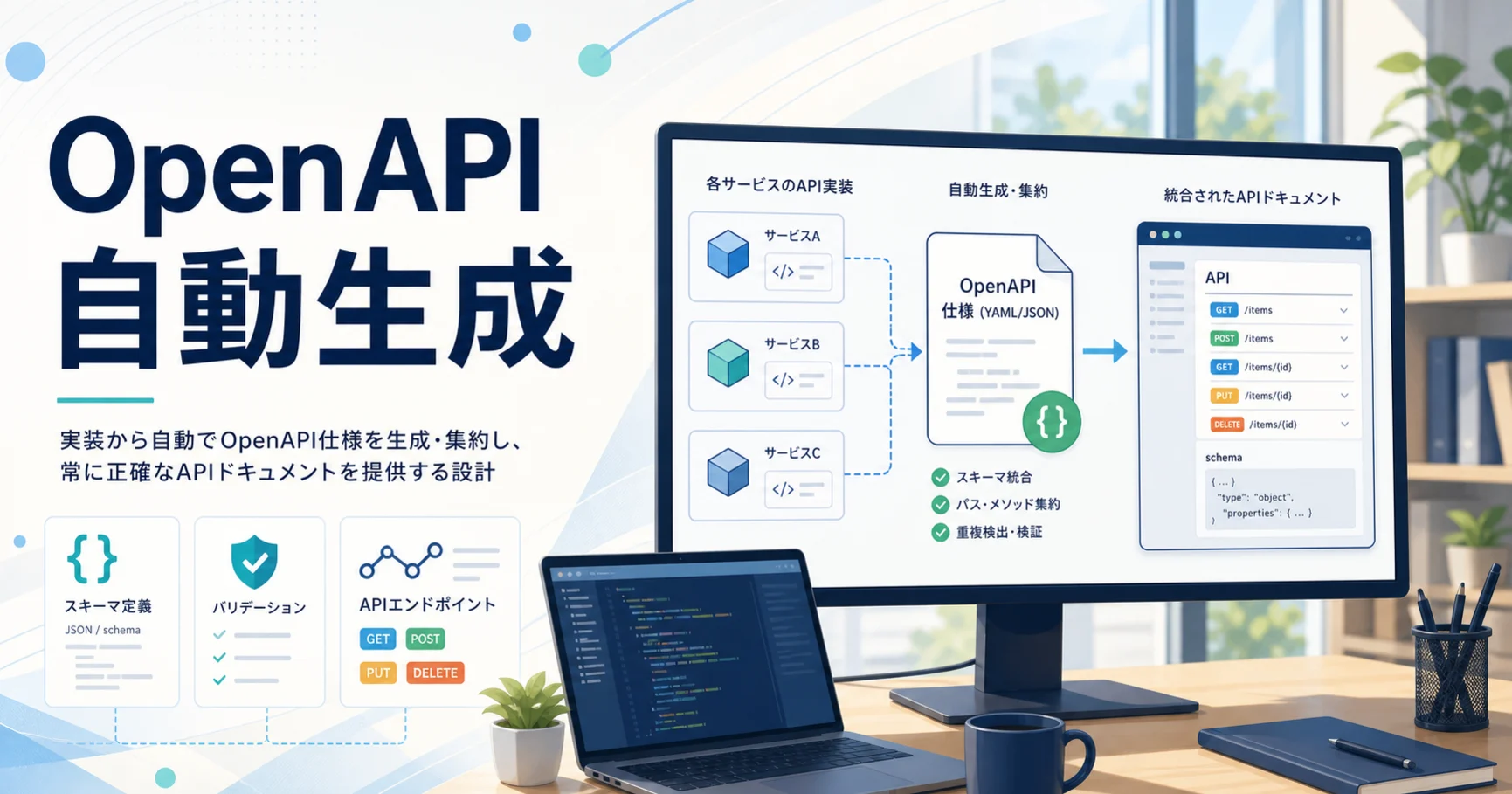
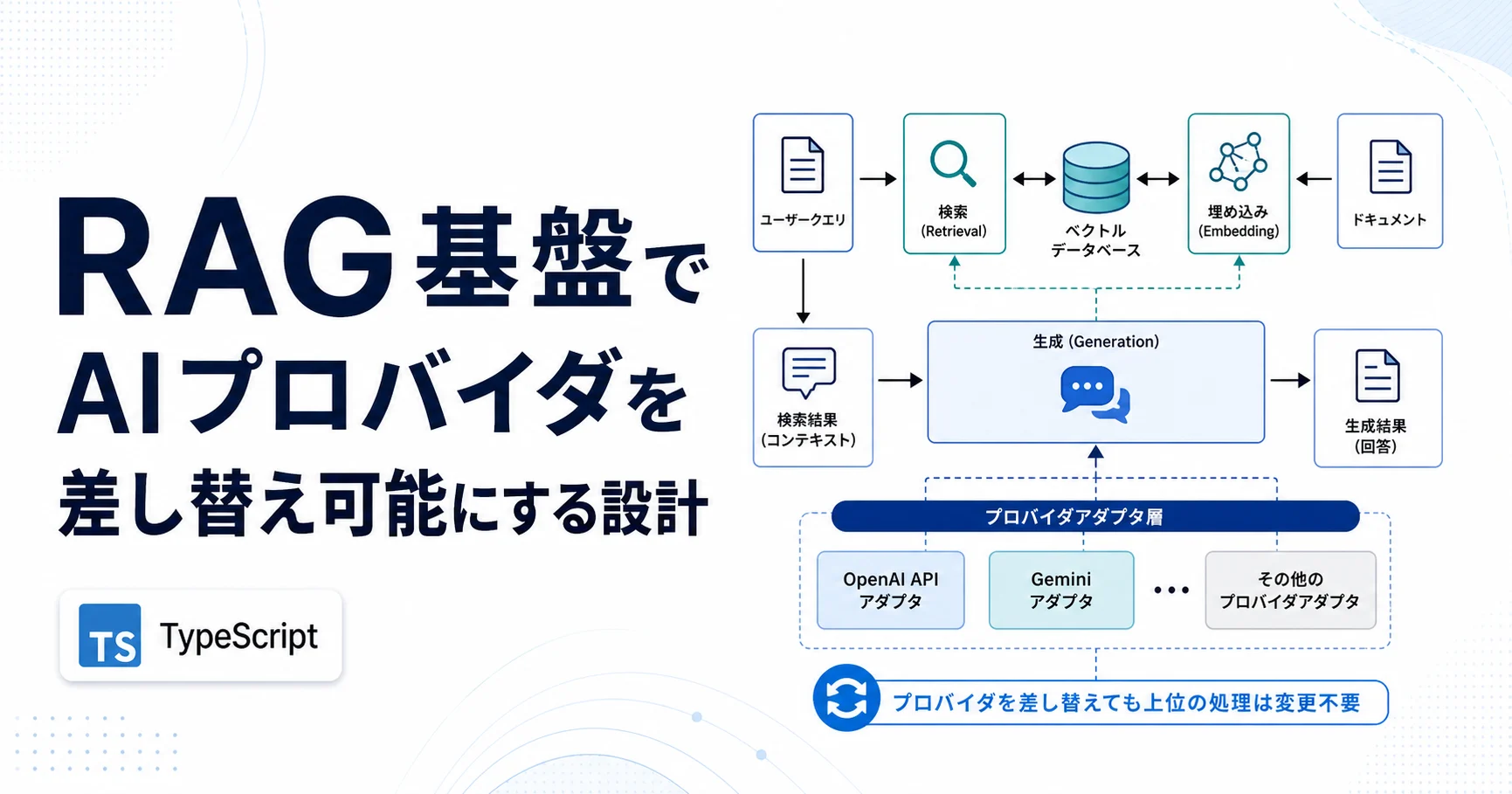
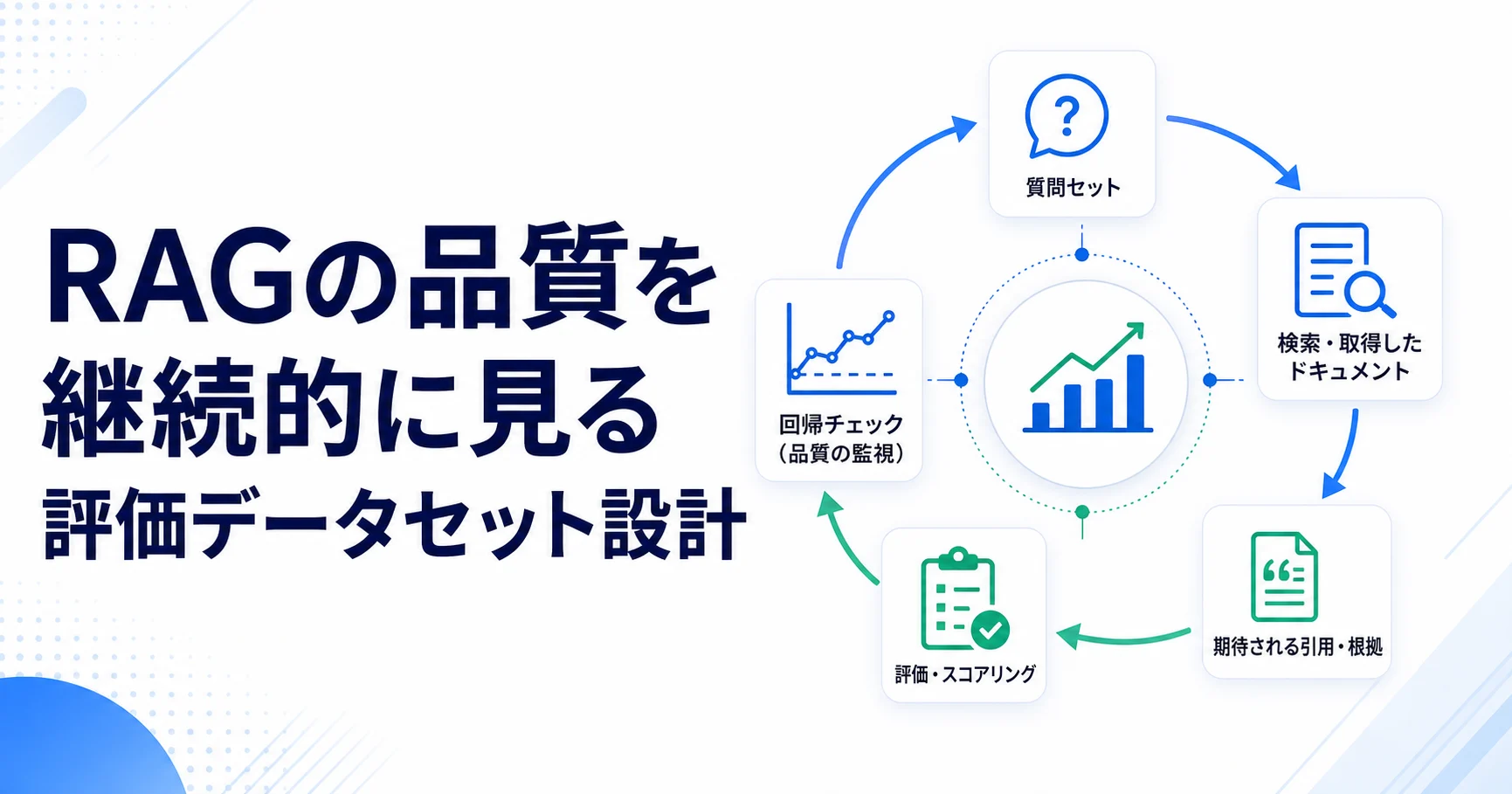
Summary
この文書の要点
- 単日の値だけでなく、本人ごとの平常値から変化を見る。
- アラートは通知ではなく確認フローとして設計する。
- 単一しきい値ではなく、時系列の変化、継続時間、過去平均との差を組み合わせる。
- アラートには発火理由、抑制理由、確認状態を残し、後から調整できるようにする。
どこが設計の難所か
活動量や開封イベントのようなデータから異常を検知する場合、単純なしきい値では個人差に対応できません。平常時から活動が少ない人と多い人を同じ基準で見ると、誤検知や見逃しが増えます。
アラートは人が確認するため、件数が多すぎると運用できません。また、データ未着、端末不調、通信遅延、本人の生活リズム変化など、異常ではない理由も多くあります。
見守りデータは、センサー値や記録が取れるほど安心に見えますが、誤検知が多いと通知が無視されます。逆に抑制しすぎると重要な変化を逃します。アラート設計は、数値判定と運用設計の中間にあります。
境界をどう切るか
設計では、本人ごとの基準値、移動平均、連続日数、急激な変化を組み合わせます。アラートは自動判断で完結させず、確認担当者が状態を更新し、理由を記録できるワークフローにします。
設計では、イベントを即通知に変換せず、観測値、判定結果、通知、確認を分けます。短時間の異常値、継続的な変化、未記録の状態を別のルールとして扱い、通知の優先度を段階化します。
実装で効く細部
PostgreSQLには日次イベント、集計値、アラート、対応履歴を分けて保存します。Hono APIでは一覧取得、担当者更新、除外理由登録を分け、React画面では地区や重要度で絞り込めるようにします。
PostgreSQLには時系列データとalert_candidates、alerts、acknowledgementsを分けて保存します。HonoやAPI層では、判定ロジックを画面から切り離し、ルールバージョンを持たせて、後からどのルールで発火したかを追えるようにします。
- しきい値は固定値だけでなく、個人ごとの平常値や時間帯を考慮できる形にする。
- 同じ原因の通知を短時間に連発しないよう、抑制ウィンドウを持つ。
- 通知後の確認、保留、誤検知のフィードバックを次のルール調整に使う。
壊れ方を観測する
検証では、過去データに対してアラートを再計算し、1日あたりの件数、誤検知率、確認に必要な時間を見ます。通知後に対応履歴が残るか、データ未着時に別扱いできるかも確認します。
検証では、過去データに対してルールを再生し、発火件数、誤検知、見逃し候補を確認します。実運用前に通知件数のシミュレーションを行うと、現場が対応できる量かどうかを判断できます。
捨てた選択肢とトレードオフ
複雑な判定にすると精度は上がる可能性がありますが、なぜ通知されたか説明しにくくなります。現場で使うアラートでは、説明可能な条件から始め、実績を見ながら調整する方が安全です。
感度を上げれば見逃しは減りますが、通知疲れが増えます。精度の高いモデルを入れても、説明できない通知は運用で受け入れられにくいです。最初は説明可能なルールを中心にし、データが蓄積してから高度化する方が堅実です。
現場に残す判断軸
見守りアラートの価値は、異常を自動で決めることではなく、人が早く確認できる状態を作ることです。誤検知を測り、対応履歴を残す設計が運用の信頼性を支えます。
見守りアラートの価値は、異常を見つけることだけではありません。なぜ通知されたかを説明でき、運用から学んで調整できる構造があることで、継続的に使える仕組みになります。