Summary
この文書の要点
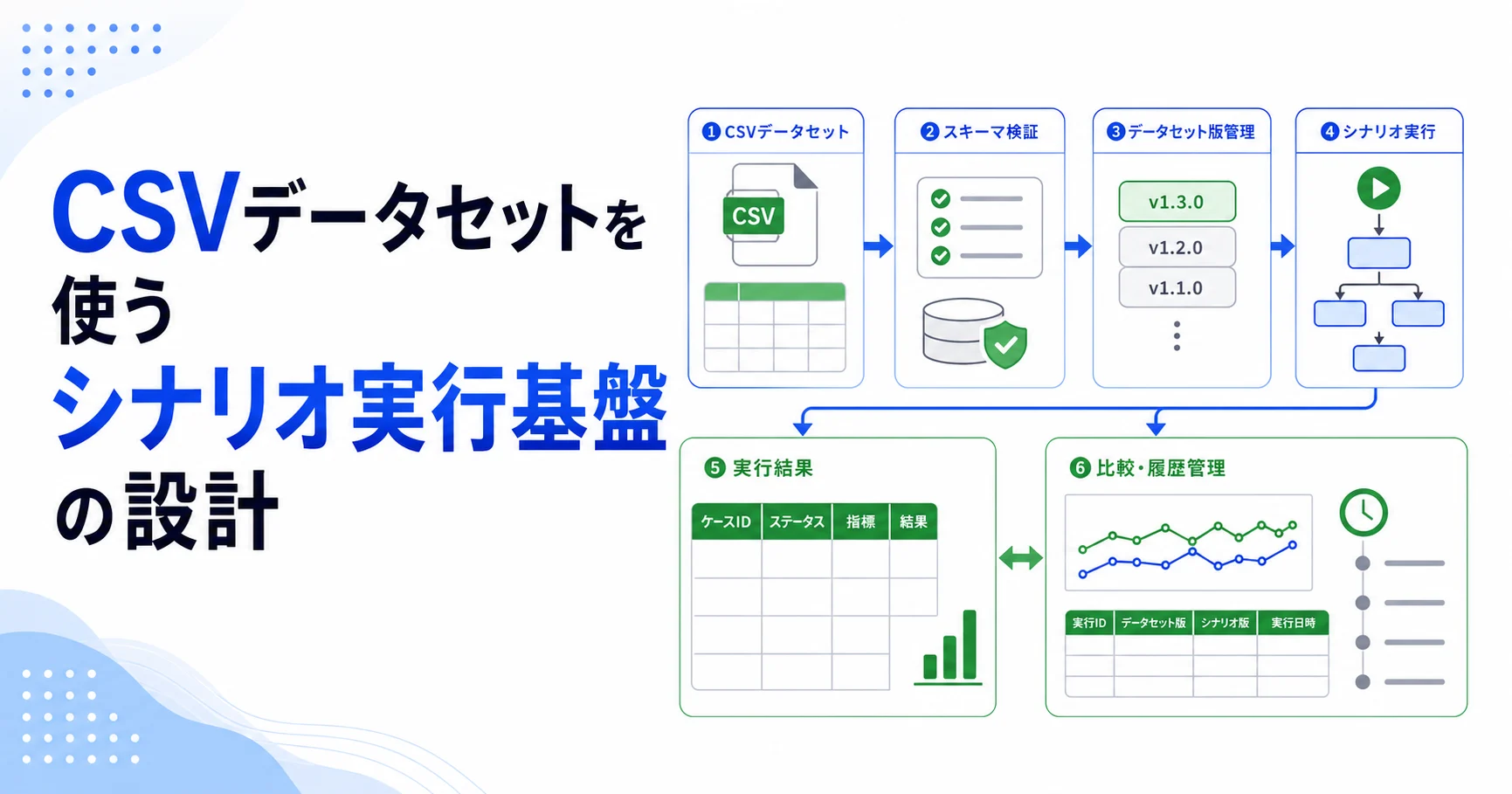
- CSVはファイルではなくデータセット版として管理する。
- 列定義と型変換を実行前に確定する。
- 入力CSV、変換ルール、期待結果、実行ログをセットでバージョン管理する。
- 失敗行だけを再実行できるように、行IDとシナリオIDを持たせる。
どこが設計の難所か
CSVをアップロードして処理するアプリでは、列名の揺れ、文字コード、改行、空白、数値形式の違いが原因で実行が失敗します。失敗してもどの行が問題か分からないと、利用者は修正できません。
CSVは外部システムや人手で作られることが多く、完全に統制できません。また、同じファイル名でも中身が変わることがあるため、実行結果を後から再現するには内容のハッシュや版管理が必要です。
CSVを使った検証は手軽ですが、ファイル名や列順、手元の修正に依存すると再現性が落ちます。シナリオ実行基盤として扱うなら、CSVは単なる入力ではなく、期待する振る舞いを固定するテスト資産です。
境界をどう切るか
取り込み時にCSVをデータセット版として保存し、ヘッダー、推定型、検証結果、ハッシュを記録します。シナリオ実行はデータセット版とパラメータを参照し、結果とエラーを別々に保存します。
設計では、データセット、シナリオ、実行、結果を分けます。CSVには業務入力に近い値を置き、別ファイルまたはメタデータで期待結果、許容誤差、スキップ条件を管理します。
実装で効く細部
FastAPIではアップロード、検証、実行、結果取得を分けます。React画面ではプレビュー、列マッピング、エラー一覧、実行履歴を表示します。大きなCSVでは全行をメモリに載せず、ストリーミングや分割処理を検討します。
FastAPIではアップロードされたCSVを検証し、実行ジョブを作成します。React側は実行状態、失敗行、差分を表示し、再実行対象を選べるようにします。結果はrun_idごとに保存し、前回実行との差分を見られるようにします。
- CSVの行には自然キーとは別にscenario_row_idを付け、失敗行を追跡する。
- 列の型変換と業務検証を分け、どこで落ちたかを分類する。
- 期待結果はCSV本体へ混ぜず、検証定義として分離する。
壊れ方を観測する
検証では、文字コード違い、列欠落、余分な列、空白行、重複キー、大容量ファイルを用意します。実行履歴から同じデータ版を再実行できること、エラー行だけを修正して再投入できることも確認します。
検証では、列欠落、余分な列、文字コード違い、桁区切り、改行混入、期待値不一致をサンプル化します。シナリオ実行そのものがテスト対象なので、実行基盤のエラー表示も確認します。
捨てた選択肢とトレードオフ
スキーマ推定を自動化しすぎると、間違った型で処理される危険があります。重要な処理では、推定結果を人が確認してから実行するステップを挟む方が安全です。
CSVは扱いやすい一方、ネスト構造や型表現には弱いです。複雑なシナリオではJSONやデータベースfixtureの方が向く場合があります。CSVは業務担当者が読める入力に限定し、検証定義は別形式にする判断が有効です。
現場に残す判断軸
CSV処理の信頼性は、アップロード後の検証と版管理で決まります。データセット版、列定義、シナリオ実行を分けることで、結果を再現しやすい処理基盤になります。
CSVシナリオは、手作業の確認をファイルにしただけでは弱いです。入力、期待、実行、差分を分けて持つと、変更の影響を継続的に確認できる基盤になります。