Summary
この文書の要点
- 変更頻度、スケーリング、権限、失敗時の影響でサービス境界を決める。
- ジョブは常駐APIとは分け、再実行性を持たせる。
- 分割単位は技術スタックではなく、変更頻度、責務、障害影響、データ所有で決める。
- サービス間通信にはIAM、タイムアウト、リトライ、相関IDを最初から設計する。
どこが設計の難所か
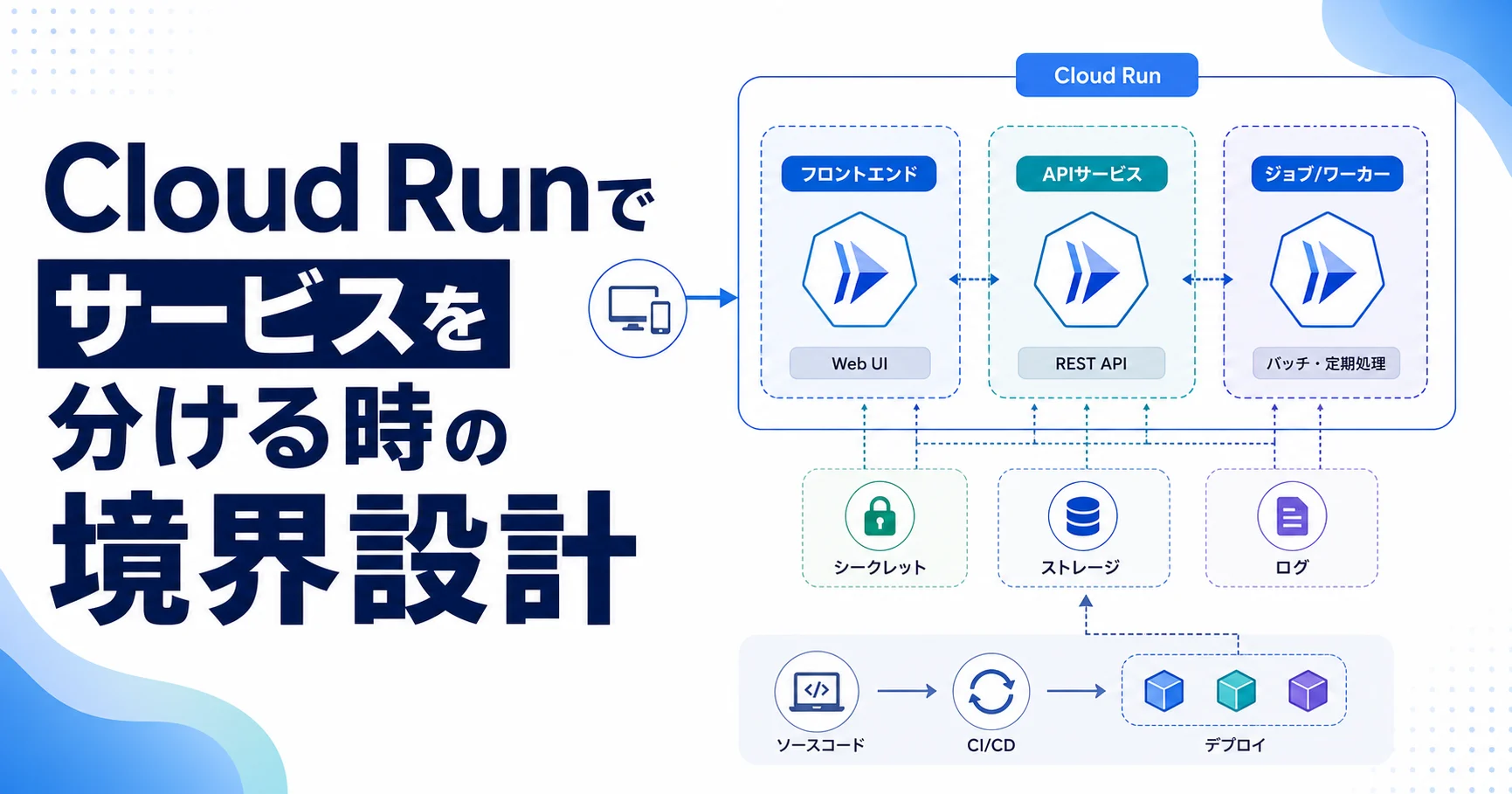
Cloud RunではコンテナをデプロイすればAPIも管理画面もジョブも動かせます。しかし責務を詰め込みすぎると、軽微な画面修正でAPIも再デプロイされ、重いバッチの失敗が通常APIの監視ノイズになります。
サービスを分けるほど、設定、ルーティング、IAM、デプロイ手順は増えます。小さな段階で過剰に分割すると運用が重くなります。分割はアーキテクチャの理想ではなく、運用上の独立性が必要になった時に行うべきです。
Cloud Runは小さなサービスを素早く公開しやすい反面、分けすぎると通信、権限、ログ、デプロイ順序が複雑になります。逆に一つにまとめすぎると、変更頻度の高い機能が全体のリリースリスクになります。
境界をどう切るか
まず、外部公開フロントエンド、認証済みAPI、非同期ジョブを分けることを検討します。変更頻度が違う、必要なSecretが違う、スケール特性が違う、失敗時に切り離したい、という条件が複数そろうものを別サービスにします。
境界は、APIの見た目ではなく運用単位で決めます。ユーザー向けWeb、管理API、バッチ、Webhook受信、重い変換処理のように、スケール条件や失敗時の影響が違うものを分けると、Cloud Runの特性を活かしやすくなります。
実装で効く細部
Dockerイメージは共通でも、Cloud Runサービスは別にできます。起動コマンドや環境変数で役割を切り替え、CI/CDでは対象ディレクトリの変更に応じて必要なサービスだけをデプロイします。ジョブはCloud Run Jobsとして定義し、手動実行と定期実行の両方を想定します。
実装では、サービスごとに環境変数、サービスアカウント、最小インスタンス、同時実行数、タイムアウトを分けます。内部呼び出しは公開URLに依存せず、IAM認証と相関IDを使い、どのリクエストがどのサービスへ渡ったかをログで追えるようにします。
- Webhook受信は短いタイムアウトでACKし、重い処理はCloud TasksやPub/Subへ逃がす。
- 管理系サービスには公開入口を絞り、サービスアカウントの権限も最小化する。
- 共通ライブラリは便利だが、DBアクセスや業務ルールを横断的に隠しすぎない。
壊れ方を観測する
検証では、サービスごとの最小権限、Secret参照範囲、ロールバック手順、ヘルスチェック、ログ検索条件を確認します。特にDBマイグレーションやデータ更新ジョブは、途中失敗時に再実行しても壊れないかを見ます。
検証では、単体のヘルスチェックだけでなく、サービス間のタイムアウト、認証失敗、片方だけ新バージョンになった状態を確認します。ログのtrace_idで一連の処理を追えることも、分割後の運用では重要なテスト観点です。
捨てた選択肢とトレードオフ
分割すると障害範囲は小さくなりますが、依存関係の管理は増えます。サービス間通信が増える場合は、認証、タイムアウト、リトライを設計しなければなりません。単純なアプリでは一体構成の方が安全なこともあります。
分割すると障害影響を閉じ込めやすくなりますが、ネットワーク遅延と運用対象は増えます。初期段階では、スケール条件や権限が明確に違う箇所だけを分け、単にファイルが大きいという理由でサービス化しない方が安全です。
現場に残す判断軸
Cloud Runのサービス分割は、きれいな図を作るためではなく、変更、権限、スケール、障害を別々に扱うために行います。分割の理由を運用言語で説明できるかが判断基準です。
Cloud Runのサービス分割は、マイクロサービス化のためではなく、変更と障害の単位を扱いやすくするために行います。分けた後のログ、権限、デプロイを説明できることが、良い境界の条件です。