Summary
この文書の要点
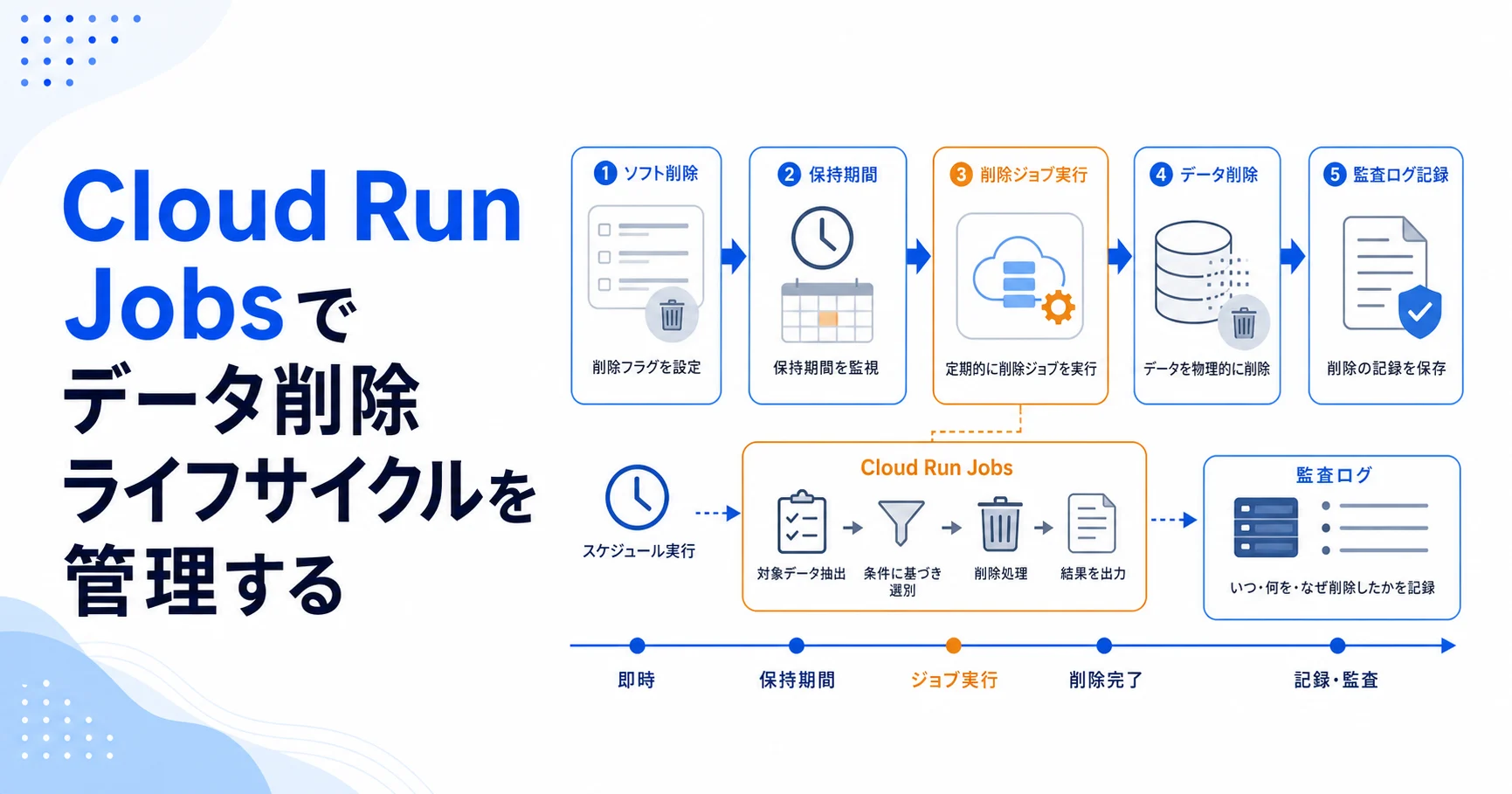
- 削除は受付、保管、物理削除の段階に分ける。
- DBレコードとGCSファイルの削除順序を明確にする。
- 削除対象の抽出、削除実行、証跡保存、失敗再試行を別ステップにする。
- Cloud Run Jobsにはdry-runと本実行を分け、対象件数を事前に確認できるようにする。
どこが設計の難所か
ユーザーが削除したデータに画像や文書ファイルが紐づく場合、DBだけ消してもストレージにファイルが残ります。逆にファイルを先に消してDB更新に失敗すると、参照できないレコードが残ります。
削除には、誤削除から戻せる期間、法的な保管期間、監査上の記録、利用者への表示など複数の要件があります。リアルタイム処理だけで完結させると、失敗時の再処理が難しくなります。
古いデータや期限切れファイルを削除する処理は、後回しにされがちです。しかし保存し続けるほどコストとリスクが増え、いざ消す時には影響範囲が分からなくなります。削除はバッチではなくライフサイクル設計です。
境界をどう切るか
削除要求時は論理削除として状態を変え、削除予定時刻を保存します。Cloud Run Jobsが期限切れデータを定期的に拾い、GCSファイル削除、DB状態更新、監査ログ記録を順番に実行します。
設計では、削除対象を直接消さず、まずcandidateとして抽出します。保持期限、法的保留、関連レコード、手動除外を確認し、削除実行後には何をいつ消したかの証跡を残します。
実装で効く細部
削除キューには対象種別、対象ID、ストレージパス、予定時刻、試行回数、最終エラーを持たせます。ジョブはバッチサイズを制限し、1件ごとに成功・失敗を記録します。GCS削除は存在しない場合も成功扱いにします。
Cloud Run Jobsでは、`--dry-run`、`--limit`、`--before-date`のような引数を持たせます。PostgreSQL上で削除候補をロックし、GCSやDBの削除を段階実行し、失敗した対象は次回再試行できる状態で残します。
- 削除候補にはreason、retention_policy_version、selected_atを保存する。
- 物理削除前に関連データの参照を確認し、孤立や参照切れを防ぐ。
- GCS削除とDB更新の順序を決め、途中失敗時の補償処理を用意する。
壊れ方を観測する
検証では、ジョブ途中失敗、同じ対象の再実行、GCSファイル欠落、DBレコード欠落、保管期間前の対象除外を確認します。削除ログから何がいつ消えたか追えることも重要です。
検証では、dry-run件数と本実行件数が一致するか、途中失敗後に再実行しても二重削除にならないかを確認します。削除対象がゼロ件の時、上限件数に達した時、権限不足の時も運用ログを見ます。
捨てた選択肢とトレードオフ
ライフサイクル管理を厳密にするとテーブルとジョブが増えます。ただし、ファイルを扱うアプリでは孤児ファイルや削除漏れが積み上がるため、初期から簡単な削除キューを持つ価値があります。
削除を慎重にしすぎるとデータが残り続け、即時削除に寄せすぎると復旧できません。論理削除期間を置いてから物理削除するなど、リスクとコストのバランスを設計する必要があります。
現場に残す判断軸
削除は単発のSQLではなく、データライフサイクルの一部です。Cloud Run Jobsのような再実行可能な仕組みに分けることで、安全に保管期間と物理削除を扱えます。
Cloud Run Jobsでの削除処理は、スケジュール実行できれば十分ではありません。対象選定と証跡をデータ化することで、削除を安全に運用できます。