Summary
この文書の要点
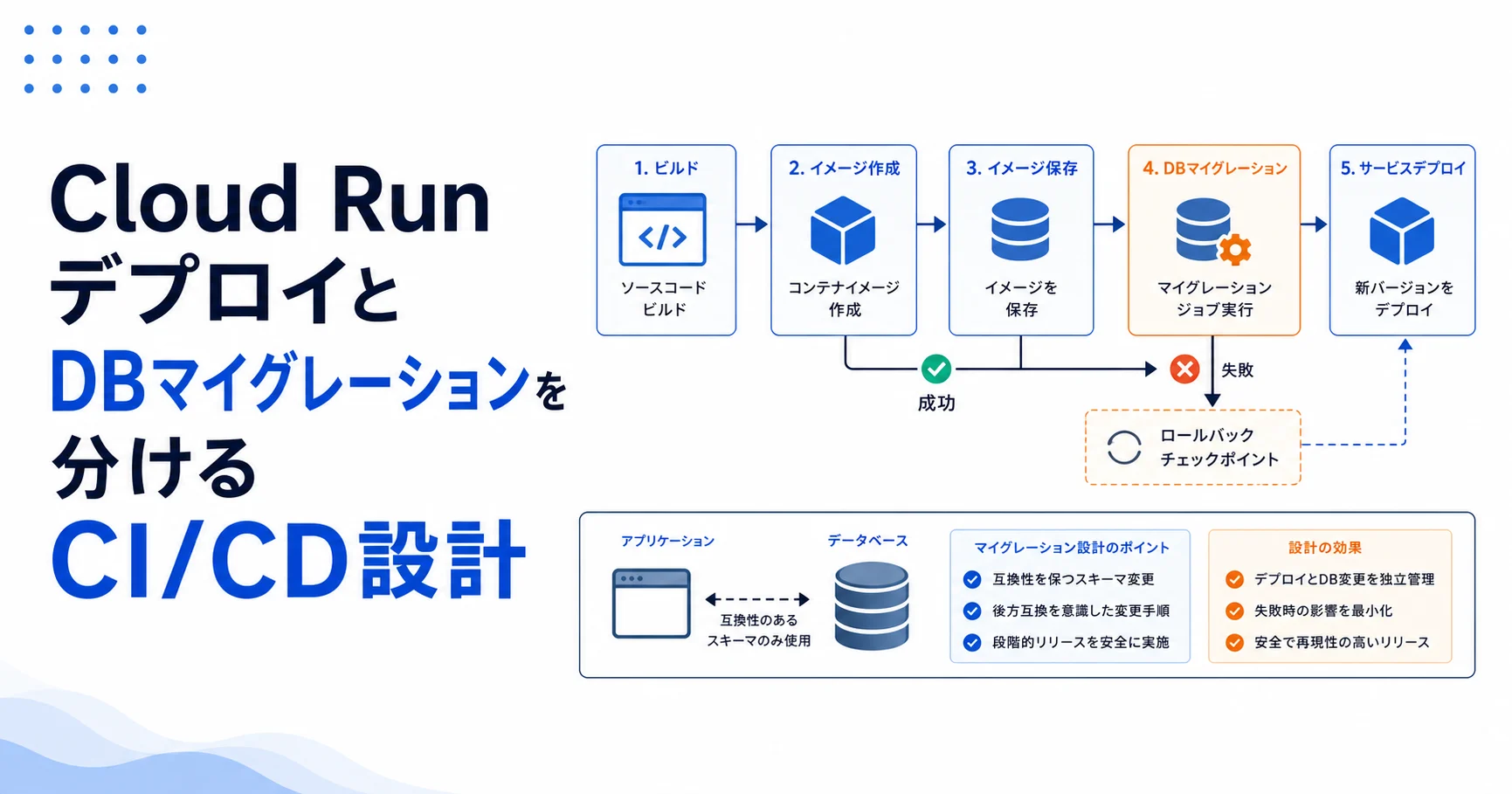
- コンテナデプロイとDBマイグレーションを同じ処理として扱わない。
- 前方互換なスキーマ変更を優先する。
- アプリデプロイ、migration実行、トラフィック切替を別ステップに分ける。
- migrationは一度だけ成功するジョブとして実行し、ログとバージョンを残す。
どこが設計の難所か
CI/CDでビルド後すぐにサービス更新とDB変更を実行すると、途中失敗時の状態が複雑になります。新しいアプリだけ戻しても、DBスキーマは戻せないことがあります。
Cloud Runはリビジョンを戻せますが、DB変更は自動では戻りません。複数インスタンスがある間、旧コードと新コードが同じDBにアクセスする時間もあります。
Cloud Runは新しいrevisionを簡単に作れますが、DBスキーマはrevisionのように並行稼働できません。アプリだけ戻せてもDB変更が残るため、デプロイとmigrationを同じ成功単位で扱うと危険です。
境界をどう切るか
安全な手順は、互換性のあるスキーマ追加、アプリデプロイ、バックフィル、制約追加、古い列削除を段階に分けることです。DBマイグレーションはCloud Run Jobsなど独立した実行単位にし、ログと終了コードを確認します。
設計では、expand migration、新アプリデプロイ、トラフィック切替、contract migrationの順に分けます。Cloud Run Jobsを使うと、migrationをアプリ起動時の副作用ではなく、明示的な実行単位として扱えます。
実装で効く細部
CIでは、Dockerビルド、テスト、イメージpush、マイグレーションジョブ実行、Cloud Runサービス更新を明示的なステップにします。危険なマイグレーションは自動実行せず、手動承認やメンテナンス手順に分けます。
CI/CDでは、コンテナビルド後にmigration jobを作成または更新し、引数でmigration方向や対象バージョンを指定します。アプリrevisionはmigration完了後にトラフィックを受け、失敗時には旧revisionへ戻せるようにします。
- アプリ起動時に自動migrationを走らせず、Cloud Run Jobsで一回だけ実行する。
- migration履歴、実行者、commit SHA、実行ログを保存する。
- 破壊的変更は旧アプリが読めなくなるため、別リリースのcontract migrationに分ける。
壊れ方を観測する
検証では、マイグレーション失敗、サービス更新失敗、旧リビジョンへのロールバック、ジョブ再実行を確認します。ステージングで本番相当のデータ量を使い、実行時間とロックを見ます。
検証では、migration job失敗時に新revisionへトラフィックが流れないこと、旧revisionが新DB状態で動くこと、再実行しても壊れないことを確認します。ステージングで本番相当のデータ量を使うとロック時間も見えます。
捨てた選択肢とトレードオフ
手順を分けるとCI/CDは長くなります。小さな変更では面倒に見えますが、戻せないDB変更を自動化しすぎる方が危険です。変更の種類に応じて自動化レベルを変えるのが現実的です。
段階リリースは手順が増えますが、失敗時の切り戻しが現実的になります。一括リリースは速いものの、DB変更で詰まると復旧が難しくなります。業務停止を避けたいなら、手順の短さより互換性を優先します。
現場に残す判断軸
Cloud Runデプロイの安全性は、リビジョン管理だけでは足りません。DBマイグレーションを独立した運用単位として扱うことで、失敗時の判断がしやすくなります。
Cloud RunのCI/CDでは、コンテナを出すこととデータ構造を変えることを分けるべきです。migrationをジョブ化すると、デプロイの失敗点を明確にできます。